如若轉載,請注明出處:http://m.520lj.com.cn/product/13.html
更新時間:2026-03-29 17:06:59
美的多款廚熱產品獲第十七屆中國家用電器創新成果證書
漯河市源匯區力之源五金機電經營部 供應產品
資訊詳情 五金機電網資訊 五金機電網
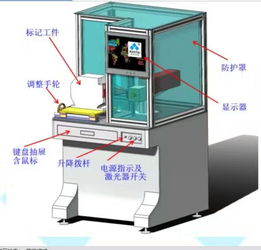
湖州知名打標機 易刻供應
鞍山市東信 東輝 物資銷售 遼寧鞍山五金工具 鞍山五金工具 電料 燈具 勞保用品 化工 五金 工具 電動工具 物資 機電 焊割工具 量具 刀具 汽車維修工具 磨料 磨具 木工 電線 電纜,,
阿米巴經營是總經理工程,咨詢老師具備什么資格條件
余姚市河姆渡鎮廣生五金電器廠 主營 五金產品的生產加工
寧波鑫隆中宏軸承 -- 中國五金機電市場網
光軸 贛州光軸 光軸價格 光軸尺寸 直線光軸廠批發
中山市南頭鎮海琴燃具五金電器廠
電話:1381772**
地址:上海市金山區張堰鎮松金公路2758號1幢A2121室
Copyright © 2026 m.520lj.com.cn 五金機電 上海覽高五金機電有限公司 五金機電 版權所有 Sitemap